共计 3816 个字符,预计需要花费 10 分钟才能阅读完成。
介绍Label Studio ML
使用 Label Studio ML Backend 将模型开发管道与数据标注工作流程整合在一起。这是一个 SDK,可以封装您的机器学习代码并将其转化为网络服务器。网络服务器可连接到正在运行的 Label Studio 实例,以自动执行标注任务。
我的信息抽取选型的PaddleNLP中的UIE,说白了就是用Label Studio ML Backend封装下UIE。
Windows
- 先搭建PaddleNLP环境,参考windows搭建paddleNLP GPU调试环境
- 启动labelstudio依赖比较多,推荐使用容器启动
docker run -it -p 8080:8080 -v $(pwd)/mydata:/label-studio/data heartexlabs/label-studio:latest浏览器输入localhost:8080,打开页面,注册一个账号,登录后见到如下界面
- 下载PaddleNLP源码,PaddleNLP-2.6.1.zip,我这里放到C:\Users\fgt\go目录下,解压
- 安装label-studio-ml-backend
cd C:\Users\fgt\go\PaddleNLP-2.6.1\model_zoo\uie
git clone https://github.com/HumanSignal/label-studio-ml-backend.git
cd label-studio-ml-backend/
pip install -e .
# 创建自己的ML backend
label-studio-ml create my_ml_backend- 自定义实现预标注功能
修改..\uie\label-studio-ml-backend\my_ml_backend\model.py 文件
from typing import List, Dict, Optional
from label_studio_ml.model import LabelStudioMLBase
from label_studio_ml.response import ModelResponse
from paddlenlp import Taskflow
import numpy as np
class NewModel(LabelStudioMLBase):
"""Custom ML Backend model
"""
def __init__(self, project_id: Optional[str] = None, label_config=None):
super().__init__(project_id, label_config)
self.from_name, self.info = list(self.parsed_label_config.items())[0]
self.to_name = self.info['to_name'][0]
self.value = self.info['inputs'][0]['value']
self.labels = list(self.info['labels'])
def setup(self):
self.set("model_version", "0.0.1")
def predict(self, tasks: List[Dict], context: Optional[Dict] = None, **kwargs) -> ModelResponse:
print(f'''\
Run prediction on {tasks}
Received context: {context}
Project ID: {self.project_id}
Label config: {self.label_config}
Parsed JSON Label config: {self.parsed_label_config}
Extra params: {self.extra_params}''')
from_name = self.from_name
to_name = self.to_name
model = Taskflow("information_extraction", schema=self.labels, task_path='./my_ml_backend/checkpoint/model_best')
predictions = []
for task in tasks:
print("predict task:", task)
text = task['data'][self.value]
uie = model(text)[0]
print("uie:", uie)
result = []
scores = []
for key in uie:
for item in uie[key]:
result.append({
'from_name': from_name,
'to_name': to_name,
'type': 'labels',
'value': {
'start': item['start'],
'end': item['end'],
'score': item['probability'],
'text': item['text'],
'labels': [key]
}
})
scores.append(item['probability'])
result = sorted(result, key=lambda k: k["value"]["start"])
mean_score = np.mean(scores) if len(scores) > 0 else 0
predictions.append({
'result': result,
# optionally you can include prediction scores that you can use to sort the tasks and do active learning.
'score': float(mean_score),
'model_version': 'uie-ner'
})
return ModelResponse(predictions=predictions)
def fit(self, event, data, **kwargs):
# use cache to retrieve the data from the previous fit() runs
old_data = self.get('my_data')
old_model_version = self.get('model_version')
print(f'Old data: {old_data}')
print(f'Old model version: {old_model_version}')
# store new data to the cache
self.set('my_data', 'my_new_data_value')
self.set('model_version', 'my_new_model_version')
print(f'New data: {self.get("my_data")}')
print(f'New model version: {self.get("model_version")}')
print('fit() completed successfully.')- 启动label-studio-ml-backend
cd C:\Users\fgt\go\PaddleNLP-2.6.1\model_zoo\uie\label-studio-ml-backend
# 启动服务 9090端口
label-studio-ml start my_ml_backend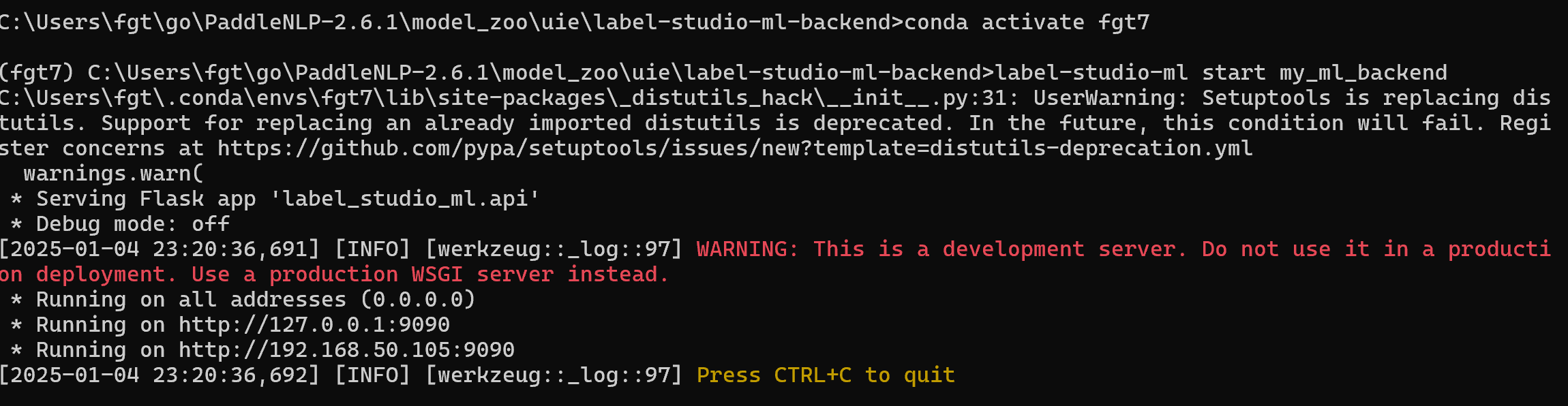
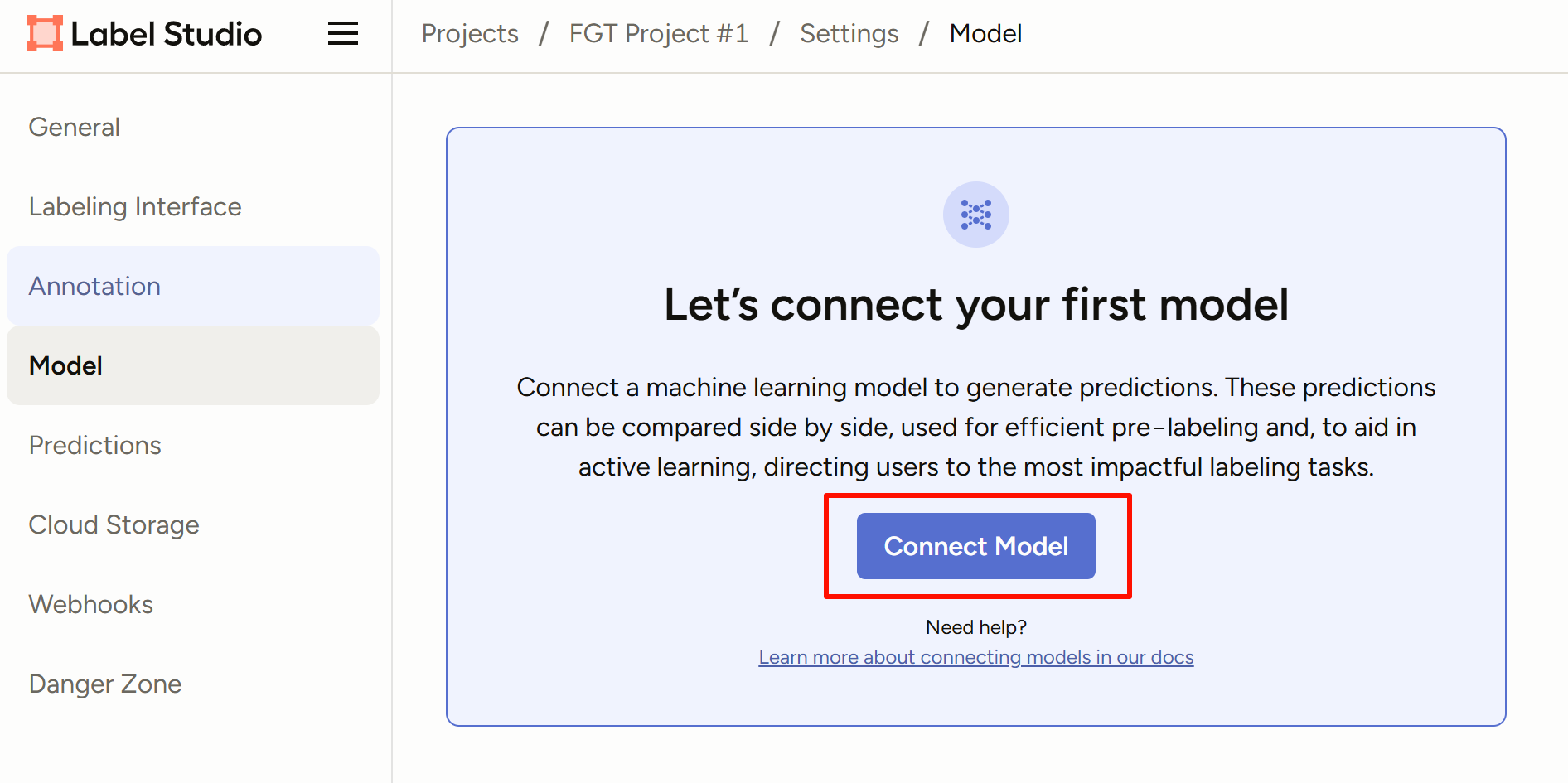
- labelstudio连接label-studio-ml-backend
进入Projects/{Project Name}/Settings/Model,Connect Model
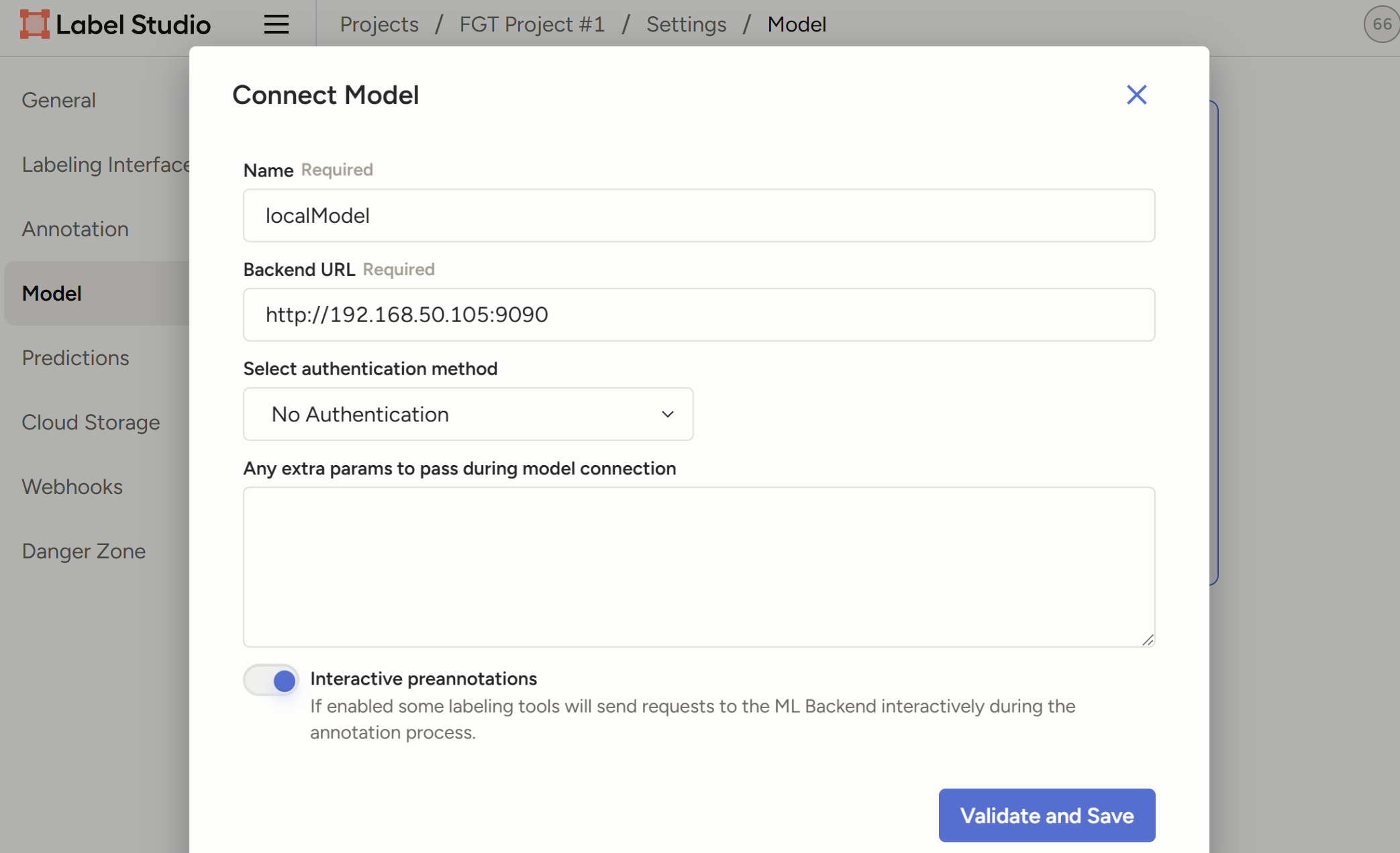
- 自动标注成功
导入数据,进入标记页面,发现自动标记成功
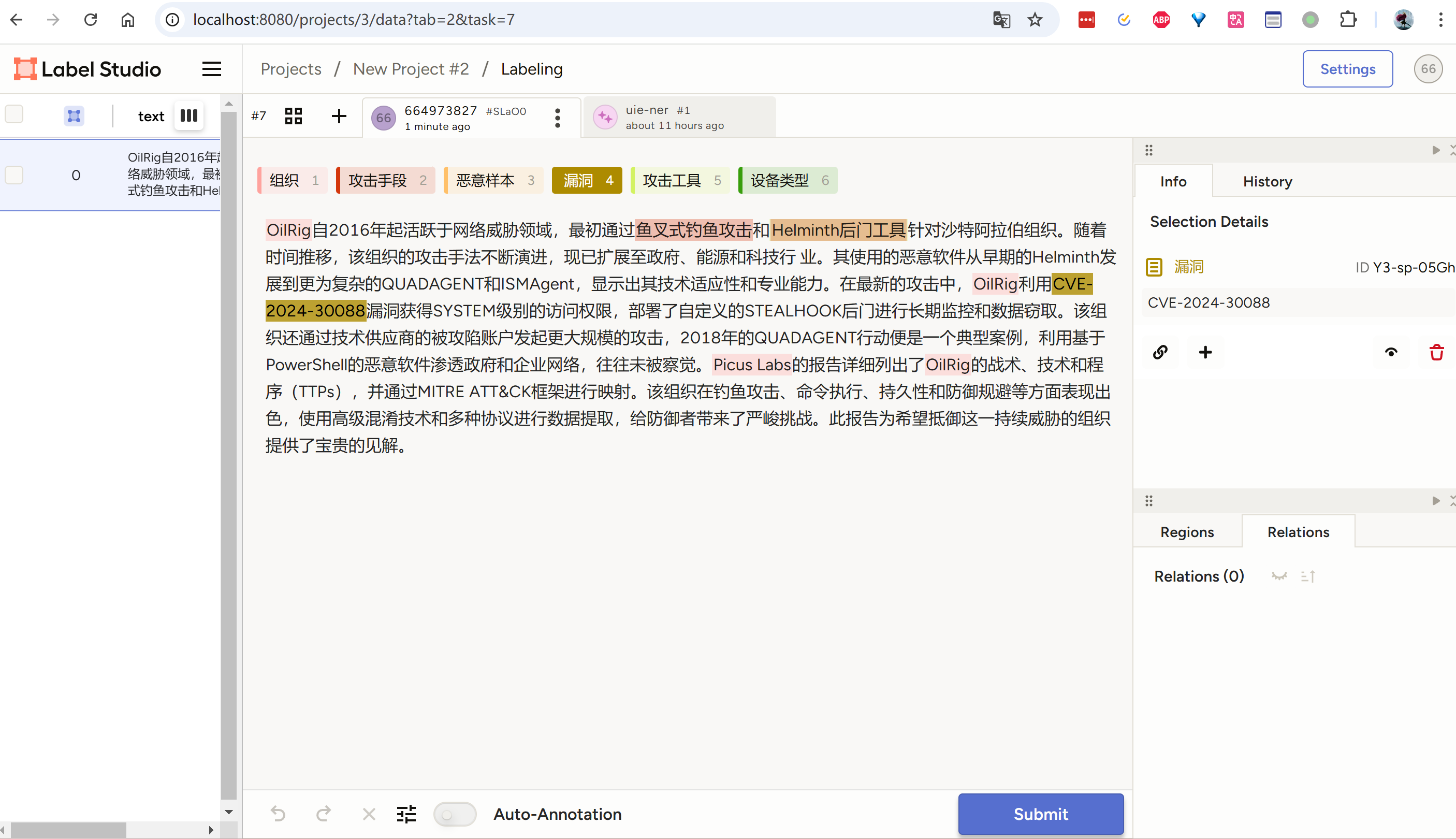
linux
- 搭建paddleNLP环境,参考Linux搭建PaddleNLP环境
- 拷贝所需文件
拷贝windows环境下的uie文件夹到linux服务器上
即拷贝C:\Users\fgt\go\PaddleNLP-2.6.1\model_zoo\uie文件夹到服务器/home/zuoyou/paddlenlp目录下
- 安装label-studio-ml-backend
# 进入paddleNLP容器内,继续安装label-studio-ml-backend
docker exec -it paddle bash
# 安装git和vim
apt update
apt install git vim
cd /uie/label-studio-ml-backend
# 安装
pip install -e .
# 启动ml服务
label-studio-ml start my_ml_backend- 提交镜像
# 功能正常,提交容器镜像,方便下次使用
docker commit paddle fgt_paddle:1.0
# 启动提交后的镜像
cd /home/zuoyou/paddlenlp/uie
docker run --name paddle -it -p 19090:9090 -v $PWD:/uie fgt_paddle:1.0 /bin/bash
# 启动ml服务
cd /uie/label-studio-ml-backend
label-studio-ml start my_ml_backend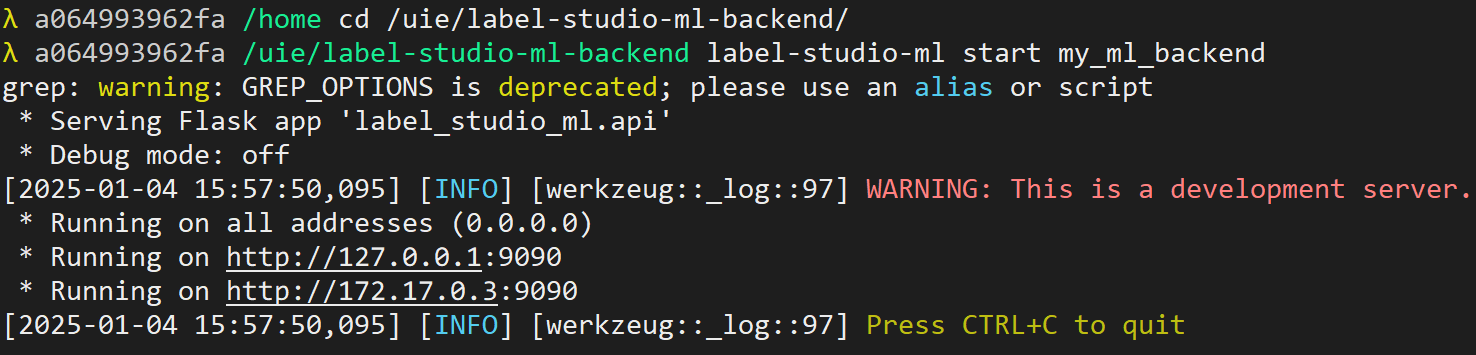
- 后面的连接labelStudio和windows一样,就不赘述了
正文完
